我们知道,web浏览器会将form中的内容打包成HTTP请求体,然后发送到服务端,服务端对请求体解析后可以得到传递的数据。这当中包含两个过程:encode与decode。
HTTP
我们使用ServerSocket搭建一个小服务器来看清http请求的全貌, 该服务器只有一个功能, 就是打印请求体。
public class HttpPrint {
private ServerSocket serverSocket;
public HttpPrint() throws IOException {
serverSocket = new ServerSocket(8080);
}
public void show() throws IOException{
while(true){
Socket socket = serverSocket.accept();
byte[] buf = new byte[1024];
InputStream is = socket.getInputStream();
ByteArrayOutputStream os = new ByteArrayOutputStream();
int n = 0;
while ((n = is.read(buf)) > -1){
os.write(buf,0,n);
}
os.close();
is.close();
socket.close();
System.out.println(os);
}
}
public static void main(String[] args) throws IOException {
new HttpPrint().show();
}
}
用html页面来发送get与post请求
<a href="http://localhost:8080/hsp?param=你好全世界">Test</a>
<form action="http://localhost:8080/hsp" method="post">
<input type="text" name="param" value="你好全世界"/>
<input type="submit"/>
</form>
启动服务器后,查看打印内容,在我的机器上,请求内容如下:
get

post
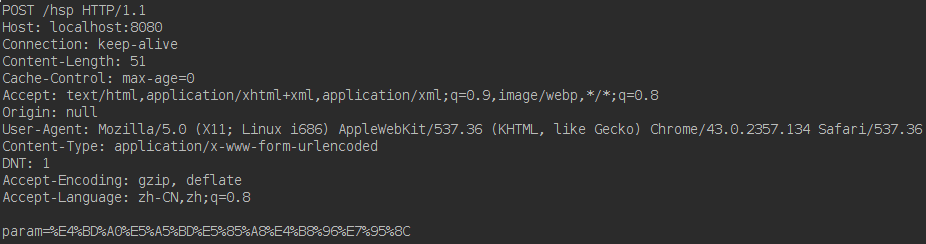
从post中的Content-Type:application/x-www-form-urlencoded可以看到,虽然数据为中文,但是在传递的时候,经过了一次urlEncode,这样一来,在数据交换层面就可以屏蔽编码的不一致性。
UrlEncode
urlEncode的任务是将form中的数据进行编码, 编码过程非常简单, 任何字符只要不是ASCII码, 它们都将被转换成字节形式, 每个字节都写成这种形式:一个 “%” 后面跟着两位16进制的数值。
urlEncode只能识别ASCII码,可以想象的是,那些urlEncode不能识别的字符,也就是十六进制数,一定是依赖于特定的字符集产生的, 字符集包括unicode,iso等。
那么浏览器用的是什么字符集呢? 答案是:默认与contentType相同, form可以通过属性accept-charset指定。
例如我们通常可以在jsp中看到这样的设置:
<%@page contentType="text/html;charset=UTF-8" %>
或者在html中这样设置:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
这表示浏览器得到响应流之后,用contentType指定的字符集,将流中的字节转换为字符,同样地,也会用这个字符集将页面中字符转换为字节。
关于浏览器设定字符集的问题,我们不过多讨论,现在只需要知道有这么个过程就行了, 需要注意的是,无论浏览器使用什么字符集,服务端都是无法获知的。 这里需要换位考虑一下,浏览器是一个客户端,应该让客户端 “迁就” 服务端, 所以浏览器请求一个服务的时候,应该让浏览器考虑服务端支持什么字符集, 得到了响应后, 用服务端告诉浏览器的字符集进行解析。
UrlDecode
现在我们将目光转向Servlet, 并使用上面的html来请求服务,请确保请求的字符集为unicode, 应用服务器使用tomcat6。
public class HttpServletPrint extends HttpServlet{
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println(req.getParameter("param"));
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doPost(req,resp);
}
}
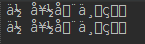
get与post结果如下,果然如预料中乱码了。
现在我们从Servlet中看看请求体, 修改上面的Servlet代码如下:
public class HttpServletPrint extends HttpServlet{
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//System.out.println(req.getParameter("param"));
byte[] buf = new byte[1024];
int n = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
InputStream is = req.getInputStream();
while ((n = is.read(buf, 0, buf.length))>-1){
bos.write(buf, 0, n);
}
String param = bos.toString();
String s = URLDecoder.decode(param,"utf-8");
System.out.println(s);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doPost(req,resp);
}
}
get与post结果如下,Servlet将http头部解析完成后,将请求体留了下来供应用程序使用, 这是考虑到http请求可能有多种 enctype , 请求体的结构可能不同,
例如,multipart/form-data就不是这样的key=value结构,关于multipart/form-data,我在这篇 fileupload 中曾有过简要分析。
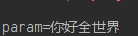
从图中可以看到, 设置了正确的字符集后, 服务端将能够正确地解析, get部分什么都没有,这是因为get没有请求体。
让我们换种字符集试试, 比如, 将servet中的”utf-8”换成”iso-8859-1”。
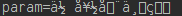
嘿,果然如我所料,而且这个字符串好像很眼熟,和req.getParameter(“param”)结果是一样的,没错,事实上,tomcat默认的字符集就是iso-8859-1, 我们从中可以得到一个推论,tomcat使用默认的字符集,对http请求进行过一次decode。
方案
urlDecode的任务是将请求中的百分号码转换成字符,显而易见的是,使用与urlEncode时相同的字符集才能成功转换。通常的做法是,让服务端支持涵盖多国语言的”utf-8”,然后让客户端也用”utf-8”请求服务。
指定服务端字符集的方式有两种,一是修改应用服务器的默认编码,二是添加一个过滤器进行编码转换, 方法一最方便, 但是影响了程序的可移植性, 方法二可移植, 它只需要做一件事:requet.setCharacterEncoding("UTF-8");,
实际上,该过滤器并没有进行任何编码转换的工作,它仅仅只是一个配置,该配置项将被后续程序使用,这些后续程序包括web服务器内置的解析程序,以及第三方解析工具等。
需要注意的是,requet.setCharacterEncoding(“UTF-8”);,只对请求体有效,也就是说,请求头不归它管,而是由web服务器采用自己配置的字符编码进行解析,此时如果url中包含中文(如get请求的参数),那么将不可避免地出现字符丢失。
解决办法是在客户端对url进行encodeURI两次, 然后再在服务端URLDecoder.decode(param,"utf-8");。
为什么要 encodeURI 两次?talk is cheap, let’s code!

注意观察这张图片,从中发现了什么? 没错,第一次encodeURI生成了HTTP一节的示例中一样的结果。
我们在浏览器窗口中输入 “http://localhost:8080/hsp?param=%E4%BD%A0%E5%A5%BD%E5%85%A8%E4%B8%96%E7%95%8C”, 会发现它变成了 “http://localhost:8080/hsp?param=你好全世界”,
在url里,浏览器认为%是个转义字符,浏览器会把%与%之间的编码,两位两位取出后进行decode, 也就是变回 “你好全世界”, 然后再用这个url发送请求, 最终实际发送的内容实际上还是%E4%BD%A0%E5%A5%BD%E5%85%A8%E4%B8%96%E7%95%8C。
换言之,以明文传递的这种url会被浏览器否决一次,再换言之,在js中进行一次encodeURI等于什么都没做。
再注意观察第2和第3个输出,有什么规律? 是的,从第二次开始encodeURI只是将%变成了%25,
根据我们刚才总结出的规律可知,在encodeURI两次的情况下,最后发送到浏览器中的数据为%25E4%25BD%25A0%25E5%25A5%25BD%25E5%2585%25A8%25E4%25B8%2596%25E7%2595%258C,
理所当然的,web服务器将使用默认的字符集对其decode, 然而, 无论选择哪种字符集, 将%25转换成%总是不会出错的, decode之后,%E4%BD%A0%E5%A5%BD%E5%85%A8%E4%B8%96%E7%95%8C 将完整地送到Servlet手上。
System.out.println(URLDecoder.decode(req.getParameter("param"),"utf-8"));
window.location.href="http://localhost:8080/hsp?param=" + encodeURI(encodeURI('你好全世界'));